안녕하세요 트윅히입니다.!!
오늘은 다시 기초 글을 작성하게 되었는데요 :)
많은 분들에게 도움이 되기를 바랍니다.~~

개발을 하다 보면 "자료구조"라는 말을 자주 듣게 됩니다.
처음엔 막연하게 느껴질 수 있지만, 사실 일상생활 속 경험과 굉장히 닮아 있어요.
오늘은 자료구조의 큰 그림부터 시작해서, 실무에서도 자주 쓰이는 스택, 큐, 이진 트리까지 함께 살펴보겠습니다! 😄
자료구조, 왜 알아야 할까?
코드를 작성할 때 데이터를 어떻게 담느냐에 따라 성능이 천지 차이가 납니다.
단순히 배열에 다 때려 넣는 것과, 상황에 맞는 자료구조를 골라 쓰는 것은 속도와 메모리 효율에서 확연한 차이가 나거든요.
자료구조를 크게 나누면 이렇습니다:
| 선형 구조 (1차원) | 배열, 스택, 큐, 연결 리스트 | 데이터가 순서대로 나열됨 |
| 비선형 구조 (2차원) | 트리, 그래프 | 계층/관계 구조, 일반적으로 성능이 더 좋음 |
💡 데이터베이스 내부도 비선형 구조인 트리를 활용합니다. 대규모 데이터에서 검색 성능을 극대화하기 위해서예요!
선형 구조 vs 비선형 구조
선형 구조는 데이터가 한 줄로 쭉 이어진 형태예요.
첫 번째 데이터 다음에 두 번째, 그 다음에 세 번째... 순서가 명확합니다.
비선형 구조는 하나의 데이터가 여러 데이터와 연결될 수 있는 형태예요.
마치 나무의 가지처럼 뻗어나가죠.
그래서 특정 데이터를 찾을 때 선형 구조보다 훨씬 빠른 경우가 많습니다.
📚 스택(Stack): 쌓고 또 쌓고
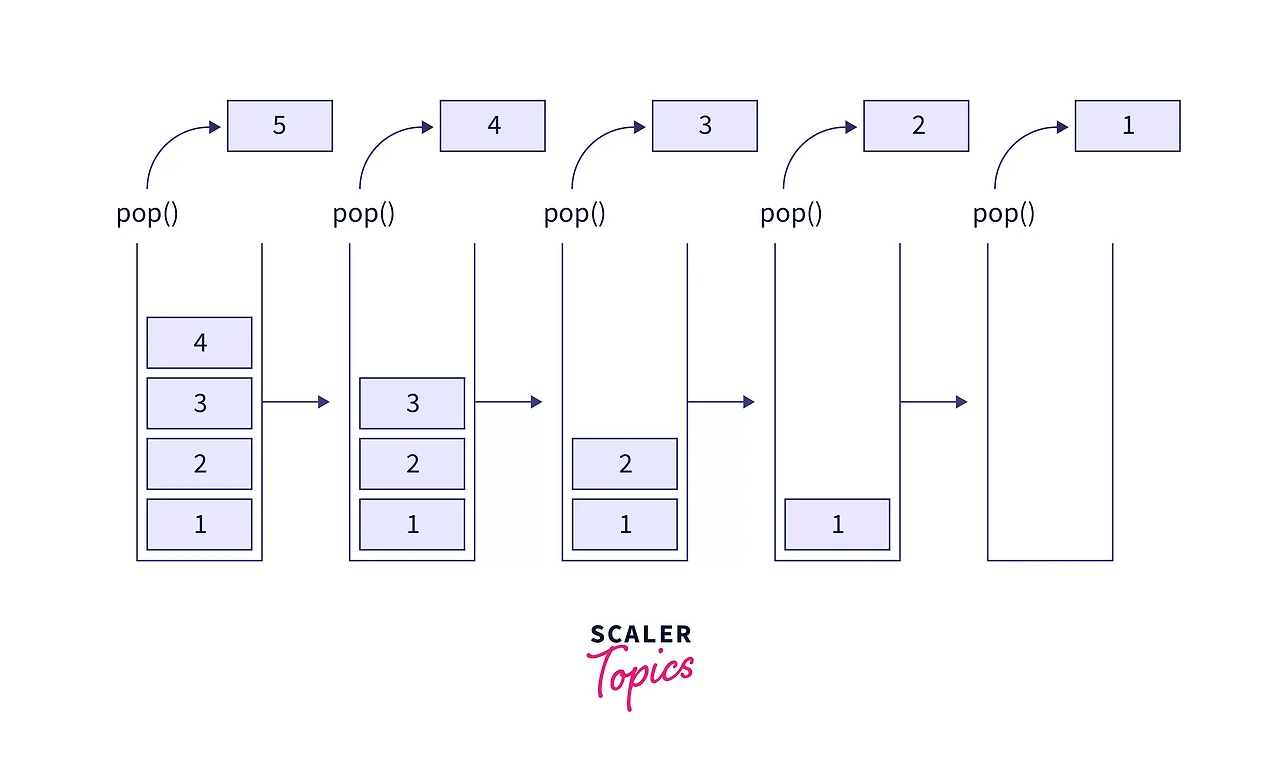
개념
스택은 LIFO(Last In, First Out) 구조입니다.
마지막에 들어온 것이 가장 먼저 나가는 방식이에요.
실생활로 비유하자면 접시 쌓기를 생각해보세요.
접시를 하나씩 위로 쌓다 보면, 맨 처음 놓은 접시는 가장 아래에 깔립니다.
꺼낼 때도 당연히 맨 위에 있는 것부터 꺼내야 하죠.
맨 밑 접시를 꺼내려면?
위에 쌓인 걸 전부 치워야 합니다. 😅
[C] ← 마지막에 들어온 것, 가장 먼저 나감 (TOP)
[B]
[A] ← 가장 처음 들어온 것 (BOTTOM)
━━━━━━━
I/O 지점 1개 (위에서만 넣고 빼기)
핵심 특징
- I/O 지점이 1개 (한 방향으로만 입출력)
- 가장 나중에 넣은 데이터가 가장 먼저 나옴
- 먼저 넣은 데이터는 나중에 꺼낼 수 있음
어디서 쓰이나요?
- 🔙 브라우저 뒤로 가기: 방문한 페이지를 스택에 쌓아두고, 뒤로 가기를 누르면 가장 최근 페이지부터 꺼냄
- ↩️ 되돌리기(Ctrl+Z): 작업 이력을 스택에 쌓아두고, 실행 취소할 때마다 하나씩 꺼냄
- 🔄 문자열 뒤집기: 문자를 하나씩 스택에 넣고 순서대로 꺼내면 역순이 됨
stack = []
# push (넣기)
stack.append("A")
stack.append("B")
stack.append("C")
# pop (빼기) → C, B, A 순서
print(stack.pop()) # C
print(stack.pop()) # B
print(stack.pop()) # A
🚌 큐(Queue): 줄 서는 자료구조

개념
큐는 FIFO(First In, First Out) 구조입니다.
먼저 들어온 것이 먼저 나가는 방식이에요.
버스 정류장을 떠올려 보세요.
먼저 줄을 선 사람이 먼저 버스에 타죠. 은행 번호표도 마찬가지예요.
먼저 온 손님이 먼저 서비스를 받습니다. 이게 바로 큐의 동작 방식이에요! 🎉
앞(Front) 뒤(Rear)
↓ ↓
[A] → [B] → [C] → [D]
↑ dequeue ↑ enqueue
(꺼내기) (넣기)
핵심 특징
- enqueue: 데이터를 뒤(Rear)에 추가
- dequeue: 데이터를 앞(Front)에서 제거
- I/O 지점이 2개 (넣는 곳과 꺼내는 곳이 분리)
어디서 쓰이나요?
- 🖨️ 프린터 인쇄 대기열: 인쇄 요청을 순서대로 처리
- 📨 메시지 큐(Message Queue): 서버 간 비동기 통신 처리
- 🔄 멀티스레드 작업 분배: 여러 작업자(Worker)가 큐에서 작업을 가져가 처리
특히 큐는 동기화에 강점이 있어요.
여러 프로세스나 스레드가 동시에 데이터를 처리할 때, 큐를 통해 순서를 보장하고 안전하게 데이터를 전달할 수 있거든요.
실무에서 Kafka, RabbitMQ 같은 메시지 큐 시스템이 널리 쓰이는 이유이기도 합니다!
from collections import deque
queue = deque()
# enqueue (넣기)
queue.append("A")
queue.append("B")
queue.append("C")
# dequeue (꺼내기) → A, B, C 순서
print(queue.popleft()) # A
print(queue.popleft()) # B
print(queue.popleft()) # C
🌳 이진 트리(Binary Tree): 두 갈래로 뻗어나가기
개념
이진 트리는 비선형 구조의 대표 주자입니다.
각 노드(데이터)가 최대 두 개의 자식 노드를 가질 수 있는 구조예요.
특히 이진 탐색 트리(Binary Search Tree, BST) 는 다음 규칙을 따릅니다:
📌 부모 노드를 기준으로, 왼쪽은 더 작은 값, 오른쪽은 더 큰 값
[8] ← 루트(Root)
/ \
[3] [10]
/ \ \
[1] [6] [14]
/ \
[4] [7]
예를 들어 숫자 카드 덱을 이진 탐색 트리로 정리하면:
- 8을 기준으로 3은 왼쪽, 10은 오른쪽
- 3을 기준으로 1은 왼쪽, 6은 오른쪽
- 이런 식으로 계속 내려가며 정렬된 형태가 만들어짐
왜 선형 구조보다 빠를까요?
배열에서 특정 숫자를 찾으려면 최악의 경우 처음부터 끝까지 전부 확인해야 합니다. (O(n))
반면 이진 탐색 트리는 루트에서 시작해 "내가 찾는 값이 현재 노드보다 작냐 크냐"만 판단하면서 절반씩 탐색 범위를 줄여나갑니다. (O(log n))
데이터가 100만 개라면?
- 선형 탐색: 최대 1,000,000번 비교
- 이진 탐색 트리: 최대 약 20번 비교 😮
찾는 값: 6
[8] → 6 < 8, 왼쪽으로
[3] → 6 > 3, 오른쪽으로
[6] → 찾았다! ✅ (단 3번 만에!)
어디서 쓰이나요?
- 🗄️ 데이터베이스 인덱스: MySQL의 B+Tree 인덱스가 대표적인 예
- 🔍 자동완성/검색 기능: 빠른 탐색이 필요한 모든 곳
- 📁 파일 시스템: 디렉토리 구조 표현
마무리
오늘 살펴본 자료구조를 한 줄로 정리하면 이렇습니다:
자료구조 방식 핵심 키워드
| 스택 | LIFO | 뒤로 가기, 되돌리기, 뒤집기 |
| 큐 | FIFO | 순서 보장, 동기화, 메시지 처리 |
| 이진 트리 | 계층 구조 | 빠른 탐색, 정렬, DB 인덱스 |
자료구조는 "어떤 게 무조건 좋다"기보다, 상황에 맞는 도구를 선택하는 게 핵심입니다.
순서를 뒤집어야 하면 스택, 순서를 지켜야 하면 큐, 빠르게 찾아야 하면 트리!
이 기준만 기억해도 실무에서 충분히 활용할 수 있을 거예요. 🚀
다음 글에서는 트리의 심화 개념인 B-Tree나 그래프 구조도 다뤄볼게요.
궁금한 점이 있으면 댓글로 남겨주세요! 😊
'✨ 1일 1개발지식' 카테고리의 다른 글
| [비전공자 전공자 되기 Part 8] 🖥️ 개발자라면 알아야 할 OS 기초 개념 총정리 (0) | 2026.04.04 |
|---|---|
| [비전공자 전공자 되기 Part 6] ☕ 자바는 컴파일러 언어일까, 인터프리터 언어일까? — 하이브리드의 비밀 (0) | 2026.03.25 |
| [비전공자 전공자 되기 Part 5] 🧠 개발자라면 알아야 할 프로그래밍 기초 개념 정리 — 고급어부터 SDK까지 (0) | 2026.03.24 |
| [비전공자 전공자 되기 Part 4] 💻 개발자라면 알아야 할 컴퓨터 개념 정리(커널과 OS..등) (1) | 2026.03.23 |
| [비전공자 전공자 되기 Part 3] 💻 컴퓨터는 어떻게 계산할까? — 디지털 회로부터 메모리 관리까지 (0) | 2026.03.22 |